| Title |
|
|
|
Ziekteleerboek
https://ziekteleerboek.wp.hum.uu.nl
|
|
|
|
CropXR
https://cropxr.org
|
|
|
|
|
|
|
Centre for Unusual Collaborations
https://unusualcollaborations.ewuu.nl
|
|
|
|
SENSIS
https://sensis.wp.hum.uu.nl
|
|
|
|
Leesevolutie
https://leesevolutie.nl
|
|
|
Handbook Challenge Based Learning
https://challengebasedlearning.ewuu.nl
|
|
|
UIearning-support
https://ulearning-support.uu.nl
|
|
Corporate UU
|
U-Talent
https://u-talent.nl
|
|
Faculty of Science
|
Artificial Intelligence
https://ai.ewuu.nl
|
|
Corporate UU
|
Geschiedenis en Didactiek
https://geschiedenisendidactiek.wp.hum.uu.nl
|
Conference | Documentation
|
Faculty of Humanities
|
Parnassos cultuurcentrum
https://parnassos.uu.nl
|
|
Corporate UU
|
Datawerkplaats
https://datawerkplaats.org
|
Research | Blog | Documentation | Information
|
Corporate UU | Faculty of Humanities | Faculty of Law, Economics and Governance | Other
|
EMLAR XX 2024
https://emlar.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Greenteens
https://greenteens.nl
|
Research | Blog | Documentation | Information
|
Faculty of Humanities
|
|
Institute for Language Sciences Labs
https://ils-labs.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
UMU - Universiteitsmuseum Utrecht
https://umu.nl
|
|
Corporate UU
|
Beyond Binaries
https://beyondbinaries.nl
|
|
Faculty of Humanities
|
Data School
https://dataschool.nl
|
Research | Blog | Documentation | Information
|
Faculty of Humanities | Other
|
|
veterinary-online-collection
https://veterinary-online-collection.eu
|
|
Faculty of Veterinary Medicine
|
|
Beyond Sharia
https://beyondsharia.nl
|
|
Faculty of Humanities
|
Professionalisering geschiedenisdocenten
Departement GKG Universiteit Utrecht
https://nascholing-gs.wp.hum.uu.nl
|
Information
|
Faculty of Humanities
|
|
IMAGINE!
https://imagine-microscopy.nl
|
|
Faculty of Science
|
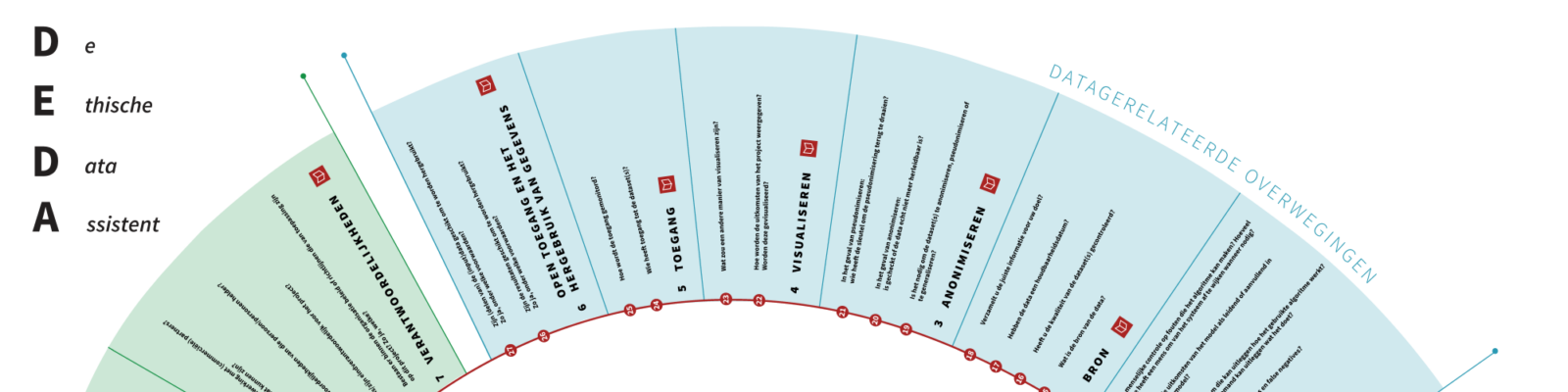
De Ethische Data Assistent (DEDA)
https://deda.dataschool.nl
|
Research | Documentation | Information
|
Corporate UU | Faculty of Humanities | Other
|
institute 4 a Circular Society
https://circularsociety.ewuu.nl
|
|
Corporate UU
|
Digital Humanities Lab
https://dig.hum.uu.nl
|
|
|
|
Lucea
https://lucea.wp.hum.uu.nl
|
|
|
|
Postgraduate Education in Toxicology
https://toxcourses.nl
|
|
Faculty of Veterinary Medicine
|
|
TAALBAAS
https://taalbaas.nu
|
|
|
|
Emblemstudies
https://emblemstudies.wp.hum.uu.nl
|
|
|
Institute 4 Preventive Health
https://preventivehealth.ewuu.nl
|
|
Corporate UU
|
|
Relation(al) Matters Archive
https://relationalmattersarchive.nl
|
|
Faculty of Humanities
|
|
Dutch Wildlife Health Centre (DWHC)
https://dwhc.nl
|
|
Faculty of Veterinary Medicine
|
Centre for Living Technologies
https://livingtechnologies.ewuu.nl
|
|
Faculty of Science
|
Global Intellectual History
https://globalintellectualhistory.org
|
|
Faculty of Humanities
|
|
NGG
https://godsdienstwetenschap.nl
|
|
|
|
Woordzoeker UU
https://woordzoeker.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Green Media Mediography
https://greenmediography.nl
|
|
Faculty of Humanities
|
|
SCOOP DB
https://scoop-db.wp.hum.uu.nl
|
|
Faculty of Social and Behavioural Sciences
|
|
Blik achteruit
https://blik-achteruit.nl
|
|
Faculty of Humanities
|
Sound memories
https://soundme.eu
|
Research
|
Faculty of Humanities
|
Challenging Future Generations
https://ewuu.nl
|
|
Corporate UU
|
|
Omstreden Zaken
https://omstredenzaken.nl
|
|
Faculty of Humanities
|
|
Masterlanguage
https://masterlanguage.nl
|
Information
|
Faculty of Humanities
|
SSH Raad
https://sshraad.nl
|
Information
|
Faculty of Humanities | Faculty of Social and Behavioural Sciences
|
|
Flexibele Nettarieven
https://ssc-fleet.nl
|
|
Corporate UU
|
Montaigne Centre Blog
https://blog.montaignecentre.com
|
Blog
|
Faculty of Law, Economics and Governance
|
U.S.V.I. Etna
https://usvietna.nl
|
|
Faculty of Humanities
|
Intimacies of Remote Warfare
https://intimacies-of-remote-warfare.nl
|
|
Other
|
|
ICO Aardwarmte
https://ico-aardwarmte.nl
|
|
|
|
Religious Matters
https://religiousmatters.nl
|
|
Faculty of Humanities
|
GOLIATH
https://beatinggoliath.eu
|
|
Faculty of Veterinary Medicine
|
Open Science Community Utrecht
https://openscience-utrecht.com
|
|
Faculty of Humanities
|
|
Carrièredag Universiteit Utrecht
https://carrieredaguu.nl
|
|
Faculty of Science
|
Studievereniging Teiresias
https://svteiresias.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Facultaire Ethische Toetsingscommissie Geesteswetenschappen
Website of the Ethical Assessment Committee Linguistics (Ethische ToetsingsCommissie Linguistiek, ETCL) and front-end to the ETCL webportal.
https://fetc-gw.wp.hum.uu.nl
|
Research | Documentation | Information
|
Faculty of Humanities
|
|
PWS Wereld
https://pws-wereld.nl
|
|
Faculty of Humanities
|
Sustainable Finance Lab
https://sustainablefinancelab.nl
|
|
Faculty of Law, Economics and Governance
|
SV Eureka
https://sveureka.nl
|
|
Faculty of Humanities
|
|
Sustainable Pension Investments Lab
https://spilplatform.com
|
|
Faculty of Law, Economics and Governance
|
Netherlands Research School of Genderstudies
https://graduategenderstudies.nl
|
|
Faculty of Humanities
|
|
Kasboekje van Nederland
https://hetkasboekjevannederland.nl
|
|
Faculty of Humanities
|
Centre for Games and Play
https://gamesandplay.nl
|
Research
|
Faculty of Humanities
|
IRIS: oplossingen voor mooier, prettiger en betaalbaar wonen in de stad Utrecht
https://iris-utrecht.nl
|
|
Other
|
How to digitise slides. Recommendations and working lists for the reproduction of a very special artefact
https://a-million-pictures-recommendations.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Monitor LAS
https://monitor-las.wp.hum.uu.nl
|
|
|
CRYSTAL
https://tki-crystal.nl
|
|
Other
|
Albion
https://albionutrecht.nl
|
|
Faculty of Humanities
|
Stichting Bedrijfsgeschiedenis
https://www.stichtingbedrijfsgeschiedenis.nl
|
|
Faculty of Humanities
|
S4 conference
The aim of the S4 Conference is to bring together international researchers working to provide Solutions for Small Sample Size and to share information, learn about new developments and discuss solutions for typical small sample size problems.
https://s4.wp.hum.uu.nl
|
Conference
|
Faculty of Social and Behavioural Sciences
|
ICT en Onderzoek
https://ictenonderzoek.wp.hum.uu.nl
|
Blog
|
Faculty of Humanities
|
Op weg naar energieleverende hoogbouwflats
https://tki-inside-out.nl
|
|
|
Werkspoorkwartier: Creatief Circulair Maakgebied
https://efro-wsk.nl
|
|
Faculty of Humanities
|
|
Monitor MCW
https://monitor-mcw.wp.hum.uu.nl
|
|
Faculty of Humanities
|
Smart Solar Charging
https://smartsolarcharging.eu
|
|
Faculty of Geosciences
|
LitLab
LitLab is een digitaal laboratorium voor literatuuronderzoek op de middelbare school.
https://litlab.nl
|
Information
|
Faculty of Humanities
|
Cultures, Citizenship and Human Rights
https://cchr.uu.nl
|
Research
|
Faculty of Humanities | Faculty of Law, Economics and Governance | Faculty of Social and Behavioural Sciences
|
|
LevelUp gamesconference
https://digra2003.org
|
|
|
|
Citizen Science
https://citizenscience.nl
|
|
|
|
GAP Summerschool
https://gap-summerschool.wp.hum.uu.nl
|
|
|
Blackboard Support
https://blackboard-support.uu.nl
|
|
Corporate UU
|
|
Persuasive Gaming in Context
https://persuasivegaming.nl
|
|
|
ARTECHNE - Technique in the Arts, 1500-1950
https://artechne.wp.hum.uu.nl
|
Research
|
Faculty of Humanities
|
Language Dynamics in the Dutch Golden Age
https://languagedynamics.wp.hum.uu.nl
|
|
Faculty of Humanities
|
Datafied Society (research platform)
https://datafiedsociety.wp.hum.uu.nl
|
Research | Blog
|
Faculty of Humanities
|
Media en Cultuur - Academische Vaardigheden en Onderzoek
https://avmec.wp.hum.uu.nl
|
|
Faculty of Humanities
|
Utrecht Centre for Television in Transition
https://tvit.wp.hum.uu.nl
|
Research
|
Faculty of Humanities
|
EDPOP: The European Dimensions of Popular Print Culture
https://edpop.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Soft Condensed Matter Group
https://colloid.nl
|
|
Faculty of Science
|
Camera Interactiva
https://camerainteractiva.org
|
|
|
|
Formulieren Geesteswetenschappen
https://forms.hum.uu.nl
|
|
Faculty of Humanities
|
Societal Resilience
https://societalresilience.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Student info ITS
ITS monitor for student information
https://its-student-monitor.wp.hum.uu.nl
|
Information
|
Corporate UU
|
https://pion.wp.hum.uu.nl
|
|
Faculty of Social and Behavioural Sciences
|
Study Association AKT
https://akt-online.nl
|
|
Faculty of Humanities
|
Syntax Interface Lectures Utrecht
Syntax Interface Lectures Utrecht
https://syntaxif.wp.hum.uu.nl
|
Conference | Research
|
Faculty of Humanities
|
Smart Sustainable Districts - Utrecht Beurskwartier
https://ssd-utrecht.nl
|
|
|
|
Monitor Applicatie GW
https://monitor-gw.wp.hum.uu.nl
|
|
Faculty of Humanities
|
Coloring Book: Testing Language Comprehension
https://coloringbook.wp.hum.uu.nl
|
Research | Blog
|
Faculty of Humanities
|
CfH Lectures
https://cfh-lectures.wp.hum.uu.nl
|
Blog | Information
|
Faculty of Humanities
|
Erasmus of Rotterdam Society
https://erasmussociety.org
|
|
Faculty of Humanities
|
A Million Pictures
https://a-million-pictures.wp.hum.uu.nl
|
|
|
Atgender
https://atgender.eu
|
Research
|
Faculty of Humanities
|
School2Work
https://school2work.wp.hum.uu.nl
|
|
Corporate UU
|
|
Stagebank Literature Today / Literatuur vandaag
https://stagebank-litto.wp.hum.uu.nl
|
|
Faculty of Humanities
|
European Network for the Study of Ancient Greek History
https://ensagh.wp.hum.uu.nl
|
|
Faculty of Humanities
|
Faculteitsraad Geesteswetenschappen
https://faculteitsraad.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Stages Geesteswetenschappen
https://stage.wp.hum.uu.nl
|
|
Faculty of Humanities
|
ILS Colloquium
https://uilotscolloquium.wp.hum.uu.nl
|
Research | Blog
|
Faculty of Humanities
|
|
Esthetica - ISSN: 1875-3809
https://estheticatijdschrift.nl
|
|
Faculty of Humanities
|
|
Annotated Books Online
https://annotatedbooksonline.com
|
|
Faculty of Humanities
|
ERC Securing Europe, Fighting its enemies, 1815-1914
https://securing-europe.wp.hum.uu.nl
|
Research
|
Faculty of Humanities
|
U2Connect
https://u2connect.org
|
|
Corporate UU
|
Fibre-Optic Monitoring van de ondergrondse Energiebalans van BodemEnergieSystemen
https://fomebes.nl
|
|
|
|
|
|
Faculty of Humanities
|
|
Monitor DGK
https://monitor-dgk.wp.hum.uu.nl
|
|
Faculty of Veterinary Medicine
|
|
Werkgroep Middelnederlandse Artesliteratuur
https://wemal.nl
|
Research
|
Faculty of Humanities
|
|
Monitor UBD
https://monitor-ubd.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Monitor UBD
https://monitor-uu.wp.hum.uu.nl
|
|
|
Sustainable Campus
https://sustainablecampus.eu
|
|
|
|
The changing face of medieval Dutch narrative literature in the early period of print (1477-c. 1540)
https://changingface.eu
|
|
Faculty of Humanities
|
Global Water Cycle Modelling
https://uu-water.wp.hum.uu.nl
|
|
|
|
VALID
https://validdata.org
|
|
Faculty of Humanities
|
|
Biogas-ETC
https://biogas-etc.eu
|
|
|
|
Philosophy After Nature
https://philosophyafternature.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Aanmelden activiteiten Geesteswetenschappen
https://aanmelden.wp.hum.uu.nl
|
|
Faculty of Humanities
|
Babylab Utrecht
https://babylab.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Platform TBE
https://platformtbe.wp.hum.uu.nl
|
|
|
|
|
|
|
|
Schwarzes Brett – Alles over Duits in Utrecht
https://schwarzesbrett.wp.hum.uu.nl
|
Blog | Information
|
Faculty of Humanities
|
Lessenreeksen over middeleeuwse literatuur
https://lesplannenmiddeleeuwen.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Institute for Language Sciences Labs
https://uilots-labs.wp.hum.uu.nl
|
|
|
|
Redrafting Perpetual Peace
https://redraftingperpetualpeace.wp.hum.uu.nl
|
|
|
|
Internships in Geosciences
https://geo-stagebank.wp.hum.uu.nl
|
|
Faculty of Geosciences
|
The Society for Emblem Studies
https://www.emblemstudies.org
|
|
Faculty of Humanities
|
|
Going Romance
https://going-romance.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Filosofisch Café Utrecht
https://filosofischcafe.wp.hum.uu.nl
|
Blog
|
Faculty of Humanities
|
Translantis
https://translantis.wp.hum.uu.nl
|
Research
|
Faculty of Humanities
|
|
VI European Congress of Methodology
https://eam2014.wp.hum.uu.nl
|
|
|
Autarkeia
https://autarkeia.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Stagebank Interculturele Communicatie
https://stagebank.wp.hum.uu.nl
|
|
|
Voting Advice Via Internet
https://vavi.wp.hum.uu.nl
|
|
Faculty of Humanities
|
|
Randomized Response
https://randomizedresponse.wp.hum.uu.nl
|
|
Faculty of Social and Behavioural Sciences
|
Medieval Literacy Platform
https://medievalliteracy.wp.hum.uu.nl
|
|
Corporate UU
|
Nederlands Genootschap voor Esthetica
https://nge.nl
|
|
Faculty of Humanities
|
Graduate Gender Programme
https://genderstudies.nl
|
|
Faculty of Humanities
|
|
Ware Bataven
https://warebataven.wp.hum.uu.nl
|
|
|
The Here and the Hereafter in Islamic Traditions
https://hhit.wp.hum.uu.nl
|
|
Faculty of Humanities
|
Multilevel Conference
The 12th International Multilevel Conference is held April 9-10, 2019. The conference will be about all aspects of statistical multilevel analysis: innovative applications, theory, software, and methodology.
https://multilevel.fss.uu.nl
|
Conference
|
Faculty of Social and Behavioural Sciences
|
|
Scaffolding Intentions
https://scaffoldingintentions.wp.hum.uu.nl
|
|
|
|
Faculty of Humanities
https://wp.hum.uu.nl
|
|
Faculty of Humanities
|